俗话说:有需求才有产出。由于经常需要整理激发态的相关跃迁信息,但每次都是人工进行Ctrl C和Ctrl V,还是感觉有点辛苦和无聊,且可能出错。秉着能被重复执行的行为,必然就会有更简单方法代替的原则。再加上大语言模型的普及,遂产生能不能用deepseek产生一个python代码的想法,帮我快速整理目标信息到表格,这样数据就可以直接被使用。
需求的产生
虽然卢天老师开发的Multiwfn软件已经非常人性化,只需将激发态计算的out/log文件,拖入Multiwfn,简单的敲击几下键盘就可以得到一个txt文件,里面包含了我们需要使用到的信息(如下图所示)。
上然的“虽然”只是为引出下文,卢老师开发的软件很好,如果没有他无私的贡献,也不会有这部分内容的产生。

但这边的需求是需要将这个文本里的信息整理到一个word表格中(如下图所示),这样就需要人工的进行好多次的Ctrl C和Ctrl V,实在是太废时间和精力。
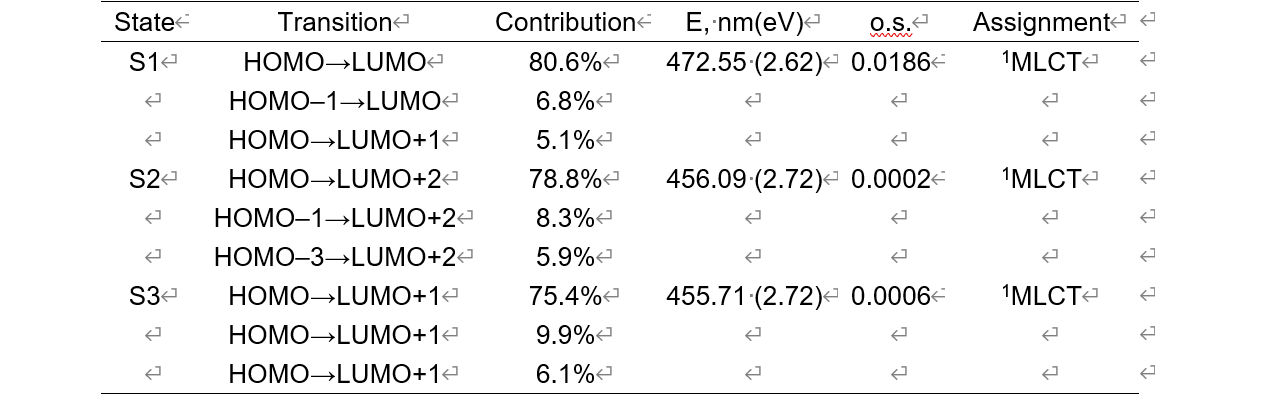
所以就在想,能不能让deepseek去生成一个python文件,当读入Multiwfn产生的txt文本文件后,将不同激发态的跃迁轨道、跃迁轨道的贡献、激发波长、激发能和振子强度整理到一个excel表中,同时设置两个阈值,分别控制跃迁轨道的贡献和振子强度,以实现输出仅大于等于振子强度阈值的激发态和大于等于跃迁轨道的贡献的跃迁轨道。最后还需要保证强制输出第一个激发态。
与deepseek的友好交流
带着这些需求,便开始与deepseek的多番交流,以及产生代码的测试。产生了以下符合上述条件的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
| import re
import pandas as pd
from pathlib import Path
def parse_excitation_data(file_path,
oscillator_strength_threshold=0.01,
transition_contribution_threshold=5.0):
with open(file_path, 'r') as file:
lines = file.readlines()
data = {
'State': [],
'Transition': [],
'Contribution': [],
'E, nm(eV)': [],
'o.s.': []
}
state_pattern = re.compile(
r'#\s*(\d+)\s*([\d.]+)\s*eV\s*([\d.]+)\s*nm\s*f=\s*([\d.]+)\s*Spin multiplicity=\s*(\d+):'
)
transition_pattern = re.compile(r'([A-Za-z0-9+-]+)\s*->\s*([A-Za-z0-9+-]+)\s*([\d.]+)%')
i = 0
first_state_processed = False
while i < len(lines):
line = lines[i].strip()
if line.startswith('#'):
match = state_pattern.match(line)
if match:
state_num = int(match.group(1))
energy = "{:.2f}".format(float(match.group(2)))
wavelength = match.group(3)
oscillator_strength = float(match.group(4))
spin_multiplicity = match.group(5)
if (not first_state_processed) or (oscillator_strength >= oscillator_strength_threshold):
i += 1
if i < len(lines):
transition_line = lines[i].strip()
transitions = []
contributions = []
for part in transition_line.split(','):
part = part.strip()
trans_match = transition_pattern.match(part)
if trans_match:
contribution = float(trans_match.group(3))
if contribution >= transition_contribution_threshold:
from_orb = trans_match.group(1).replace('H', 'HOMO').replace('L', 'LUMO').replace('-', '–')
to_orb = trans_match.group(2).replace('H', 'HOMO').replace('L', 'LUMO').replace('-', '–')
contribution_str = f"{contribution}%"
transitions.append(f"{from_orb}→{to_orb}")
contributions.append(contribution_str)
if transitions:
for j in range(len(transitions)):
data['State'].append(f"S{state_num}" if j == 0 else "")
data['Transition'].append(transitions[j])
data['Contribution'].append(contributions[j])
data['E, nm(eV)'].append(f"{wavelength} ({energy})" if j == 0 else "")
data['o.s.'].append(oscillator_strength if j == 0 else "")
if not first_state_processed:
first_state_processed = True
i += 1
return pd.DataFrame(data)
def save_to_excel(df, output_file):
try:
output_path = Path(output_file)
output_path.parent.mkdir(parents=True, exist_ok=True)
df.to_excel(output_file, index=False, sheet_name='Sheet1')
print(f"文件已成功保存到 {output_file}")
except PermissionError as e:
print(f"权限错误:{e}")
print("建议操作:")
print("1. 关闭Excel或其他正在使用该文件的程序")
print(f"2. 检查是否有权写入目录:{output_path.parent}")
print("3. 尝试使用其他路径,如桌面目录")
except Exception as e:
print(f"保存失败:{e}")
if __name__ == "__main__":
input_file = 'sample_exc.txt'
output_file = 'excitation_states.xlsx'
osc_threshold = 0.01
contrib_threshold = 5.0
user_input_osc = input(f"请输入振子强度阈值(默认值为 {osc_threshold},S1将始终输出): ")
if user_input_osc.strip():
try:
osc_threshold = float(user_input_osc)
except ValueError:
print("输入无效,使用默认振子强度阈值。")
user_input_contrib = input(f"请输入跃迁贡献阈值(%)(默认值为 {contrib_threshold},小于此值的跃迁将被过滤): ")
if user_input_contrib.strip():
try:
contrib_threshold = float(user_input_contrib)
except ValueError:
print("输入无效,使用默认跃迁贡献阈值。")
df = parse_excitation_data(input_file, osc_threshold, contrib_threshold)
save_to_excel(df, output_file)
|
首先,使用该部分代码,需要确保你运行的python安装了re、pandas、pathlib这三个库。其次,将待处理文件改名为sample_exc.txt。接着,将上述代码保存为sample_exc.py且与sample_exc.txt在同一个文件夹中。最后,命令行运行python sample_exc.py,应该就可以产生一个excitation_states.xlsx的文件,excel中的内容大概如下图所示,只需要将内容粘贴到word中即可。
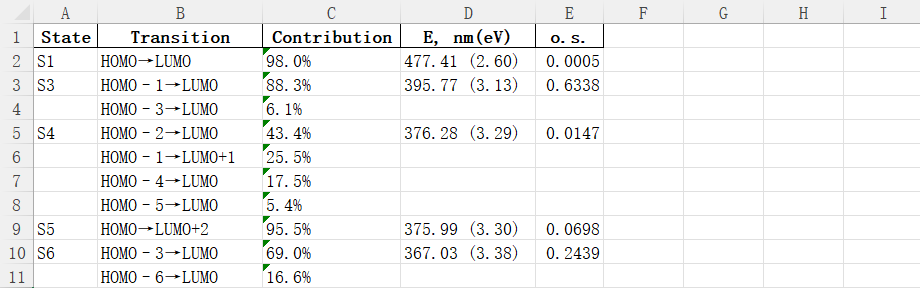
当然建议上述python操作,最好是在虚拟环境中运行,感觉会比较安全,在运行时,只需要在对应的虚拟环境中安装对应的库即可。
最后
通过这个例子可以看出,将一些简单但需要重复的事,交给deepseek这种大语言模型完全是可行,像我这样一个对python并不是很懂的人,也可以借助与大语言模型的交流,来解决实际工作中的问题。总之,学习一直在路上。